Last week, got this issue reported by a DBA that he wasn’t able to su to oracle user from root on a Oracle Base Database VM in OCI. The login of opc user worked fine and he could do sudo su to root but he couldn’t su to oracle. When he did it just came back to root shell.
[root@xxx ~]# su - oracle
Last login: Fri Jan 12 10:20:38 UTC 2023
[root@xxx ~]#
There was nothing relevant in /var/log/messages or /var/log/secure. I tried it for some other user and it worked fine. Then I suspected something with the profile of oracle user and voila ! The .bashrc looked like this
So the moment it logged in with user oracle, there was an exit command in .bashrc and it used to exit. Problem solved. I don’t know who did it but it looks like a mischief done by someone.
To put it in bit of an Indian context, database is not your daughter-in-law that you can blame it for every performance issue that occurs in the environment. But it does happen. Most of the time it is the database that is blamed for all such issues. Many times, the issues are in some other layer like OS, network or storage.
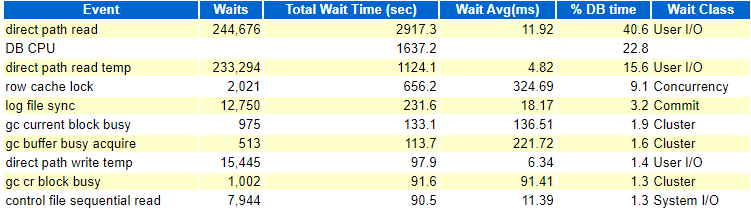
Faced this issue recently at one of the customer sites where performance in one of the databases went down suddenly. It was a 2 node RAC on 12.1.0.2 running on Linux 7 using some kind of Hitachi SSD storage array. There were no changes as per DBA, application, OS and storage teams. But something must have changed somewhere. Otherwise why would performance degrade just like that. I & my colleague checked some details and found that something happened in the morning a day before. Starting from that point in time, the execution time for all the commonly run queries shot up. Generally speaking, when all the queries are doing bad and you are sure that nothing has been changed on the database side, the reasons could be outside the database. But being a DBA, it is not easy to prove that. We took AWRs from good and bad times and the wait events section looked like this:
Now there is something clearly and terribly wrong with the details in the second snippet and in the first look it appears to be an IO issue. Av Rd(ms) in the File IO Stats section of the AWR reports was also showing really bad numbers for most of the data files, which have been fine two days ago.
The conference calls continued and we were not reaching anywhere. Storage team as usual said that everything was fine and there were no issues. Finally the discussion moved to multipathing and the teams started checking in that direction. There were errors like this in /var/log/messages
multipathd: asm!.asm_ctl_vbg1: failed to get path uid
multipathd: asm!.asm_ctl_vbg6: failed to get path uid
multipathd: asm!.asm_ctl_vbg9: failed to get path uid
That meant there was a problem with one of the paths from the database nodes to storage. They disabled the bad path for both the DB nodes and voila ! IO performance was back on track. It was multipathing that needed to be fixed.
So it is always not the database. It is unfair to always blame the DBA !
One of my friend today asked me about removing Linux partitions & GRUB (from a dual boot system) and return back to windows alone. Removing Linux involves just formatting/removing the partitions. Now to remove GRUB either do fdisk /mbr from a Windows 98 bootable CD or do fixmbr after booting into repair mode with Windows XP CD. But if you have none then to remove GRUB you will need some utility like this one and if you reboot before doing that it might make GRUB unable to boot into Windows. It will get stuck at GRUB> prompt only. So there is an option: to manually boot the OS you want (ie Windows). A quick search gave link to this thread. It involves few commands on the GRUB prompt: