To put it in bit of an Indian context, database is not your daughter-in-law that you can blame it for every performance issue that occurs in the environment. But it does happen. Most of the time it is the database that is blamed for all such issues. Many times, the issues are in some other layer like OS, network or storage.
Faced this issue recently at one of the customer sites where performance in one of the databases went down suddenly. It was a 2 node RAC on 12.1.0.2 running on Linux 7 using some kind of Hitachi SSD storage array. There were no changes as per DBA, application, OS and storage teams. But something must have changed somewhere. Otherwise why would performance degrade just like that. I & my colleague checked some details and found that something happened in the morning a day before. Starting from that point in time, the execution time for all the commonly run queries shot up. Generally speaking, when all the queries are doing bad and you are sure that nothing has been changed on the database side, the reasons could be outside the database. But being a DBA, it is not easy to prove that. We took AWRs from good and bad times and the wait events section looked like this:
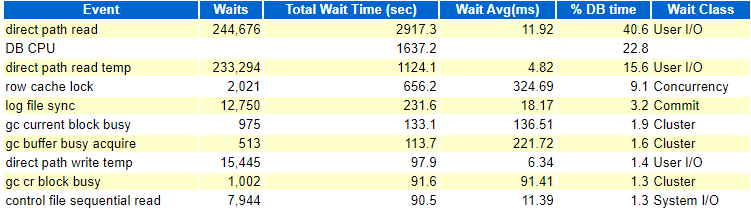

Now there is something clearly and terribly wrong with the details in the second snippet and in the first look it appears to be an IO issue. Av Rd(ms) in the File IO Stats section of the AWR reports was also showing really bad numbers for most of the data files, which have been fine two days ago.
The conference calls continued and we were not reaching anywhere. Storage team as usual said that everything was fine and there were no issues. Finally the discussion moved to multipathing and the teams started checking in that direction. There were errors like this in /var/log/messages
multipathd: asm!.asm_ctl_vbg1: failed to get path uid
multipathd: asm!.asm_ctl_vbg6: failed to get path uid
multipathd: asm!.asm_ctl_vbg9: failed to get path uid
That meant there was a problem with one of the paths from the database nodes to storage. They disabled the bad path for both the DB nodes and voila ! IO performance was back on track. It was multipathing that needed to be fixed.
So it is always not the database. It is unfair to always blame the DBA !